Chapter 1.5 - Track model evolution with DVC¶
Introduction¶
In the previous chapter, you did set up a DVC pipeline to reproduce your experiment.
Once this stage is created, you will be able to change our model's configuration, evaluate the new configuration and compare its performance with the last committed ones.
In this chapter, you will learn how to:
- Update the parameters of the experiment
- Reproduce the experiment
- Visualize the changes made to the model
Let's get started!
Steps¶
Update the parameters of the experiment¶
Update your experiment with the following parameters by editing the params.yaml file:
| params.yaml | |
|---|---|
Check the differences with Git to validate the changes:
| Execute the following command(s) in a terminal | |
|---|---|
The output should be similar to this:
Here, you simply changed the epochs parameter of the Train stage, which should slightly affect the model's performance.
Reproduce the experiment¶
Let's discover if these changes are positive or not! To do so, you will need to reproduce the experiment:
| Execute the following command(s) in a terminal | |
|---|---|
Compare the two iterations¶
You will now use DVC to compare your changes with the last committed ones. For DVC, HEAD refers to the last commit on the branch you are working on (at this moment, the branch main), and workspace refers to the current state of your working directory.
Note
Remember? You did set the parameters, metrics and plots in the previous chapter: Chapter 1.4: Reproduce the ML experiment with DVC.
Compare the parameters difference¶
In order to compare the parameters, you will need to use the dvc params diff. This command will compare the parameters that were set on HEAD and the ones in your current workspace:
| Execute the following command(s) in a terminal | |
|---|---|
The output should look like this:
DVC displays the differences between HEAD and workspace, so you can easily compare the two iterations.
Compare the metrics difference¶
Similarly, you can use the dvc metrics diff command to compare the metrics that were computed on HEAD and the ones that were computed in your current workspace:
The output should look like this:
Again, DVC shows you the differences, so you can easily compare the two iterations. Here, you can see that the metrics have slightly improved.
Compare the plots difference¶
Finally, you can use the dvc plots diff command to compare the plots that were generated on HEAD and the ones that were generated in your current workspace:
| Execute the following command(s) in a terminal | |
|---|---|
Tip for WSL2 users
When using WSL2, this command will not succeed by default but the report is available by clicking on the dvc_plots/index.html file.
The Linux distribution is accessible through the \\wsl.localhost\ address in the file explorer. The current directory can also be opened directly from the shell with the explorer.exe . command.
Warning
Do not enable auto-opening using the suggested command dvc config plots.auto_open true, as this will cause complications in subsequent steps.
The effect of the dvc plots diff command is to create a dvc_plots directory in the working directory. This directory contains a report to visualize the plots in a browser.
As for the other commands, DVC shows you the differences so you can easily compare the two iterations.
Here is a preview of the report:
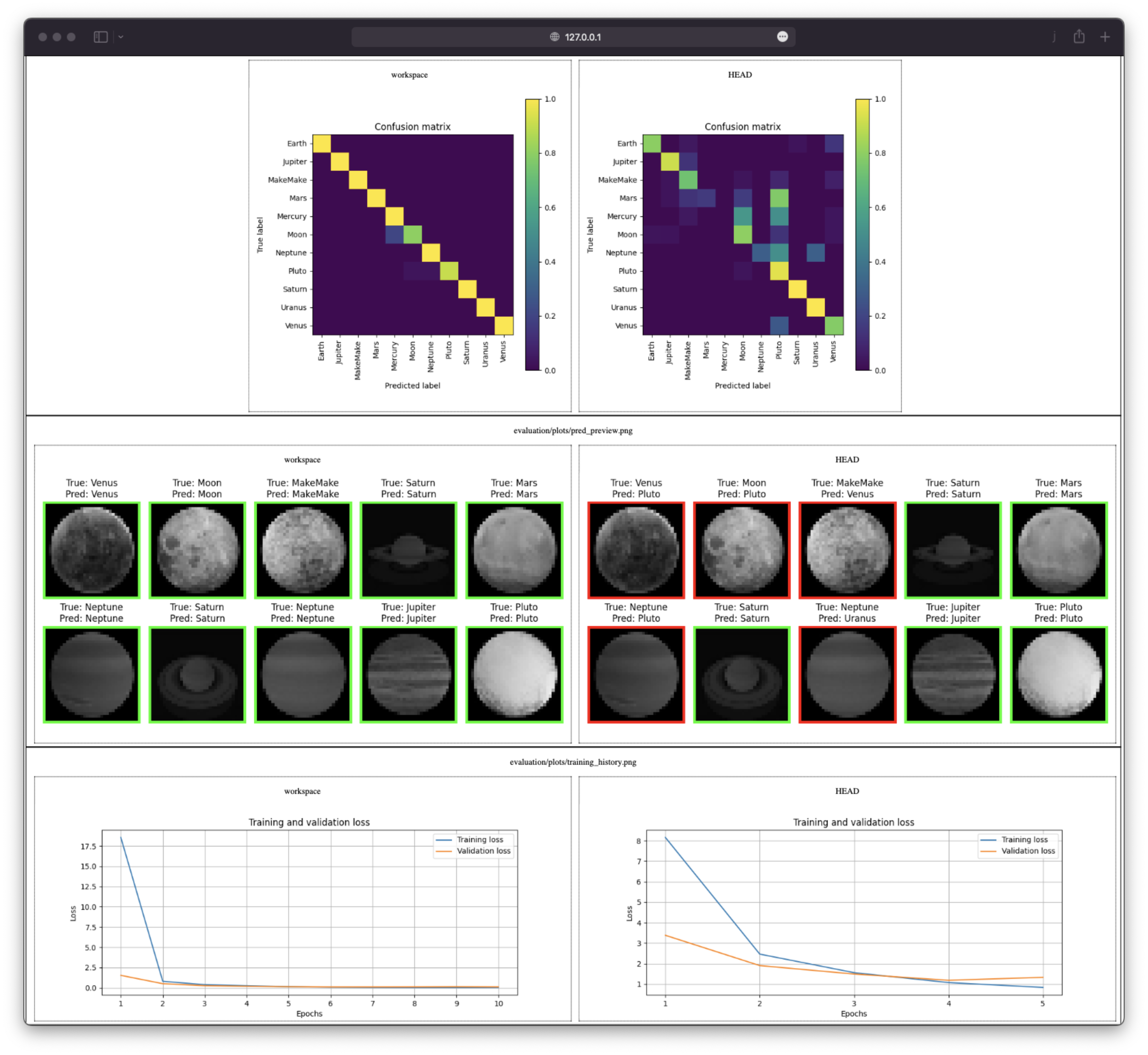
Summary of the model evolutions¶
You should notice the improvements made to the model thanks to the DVC reports. These improvements are small but illustrate the workflow. Try to tweak the parameters to improve the model and play with the reports to see how your model's performance changes.
Update the .gitignore file¶
The dvc plots diff creates a dvc_plots directory in the working directory. This directory should be ignored by Git.
Add the dvc_plots directory to the gitignore file:
| .gitignore | |
|---|---|
Info
If using macOS, you might want to ignore .DS_Store files as well to avoid pushing Apple's metadata files to your repository.
Check the differences with Git to validate the changes:
| Execute the following command(s) in a terminal | |
|---|---|
The output should be similar to this:
Check the changes¶
Check the changes with Git to ensure that all the necessary files are tracked:
| Execute the following command(s) in a terminal | |
|---|---|
The output should look like this:
Commit the changes¶
Commit the changes to the local Git repository:
| Execute the following command(s) in a terminal | |
|---|---|
This chapter is done, you can check the summary.
Summary¶
Congratulations! You now have a simple way to compare the two iterations of your experiment.
In this chapter, you have successfully:
- Updated the experiment parameters
- Reproduced the experiment
- Visualized the changes made to the experiment
- Commited the changes
You fixed some of the previous issues:
- The changes done to a model can be visualized with parameters, metrics and plots to identify differences between iterations
You have solid metrics to evaluate the changes before integrating your work in the code codebase.
You can now safely continue to the next chapter.
State of the MLOps process¶
- Notebook has been transformed into scripts for production
- Codebase and dataset are versioned
- Steps used to create the model are documented and can be re-executed
- Changes done to a model can be visualized with parameters, metrics and plots to identify differences between iterations
- Codebase requires manual download and setup
- Dataset requires manual download and placement
- Experiment may not be reproducible on other machines
- CI/CD pipeline does not report the results of the experiment
- Changes to model are not thoroughly reviewed and discussed before integration
- Model may have required artifacts that are forgotten or omitted in saved/loaded state
- Model cannot be easily used from outside of the experiment context
- Model requires manual publication to the artifact registry
- Model is not accessible on the Internet and cannot be used anywhere
- Model requires manual deployment on the cluster
- Model cannot be trained on hardware other than the local machine
- Model cannot be trained on custom hardware for specific use-cases
You will address these issues in the next chapters for improved efficiency and collaboration. Continue the guide to learn how.
Sources¶
Highly inspired by: